"Self-improving AI agent" sounds bigger than it is. The practical version is closer to a good engineering loop. The agent runs, fails, leaves evidence, proposes a change, and proves that the change generalizes before it becomes default behavior.
The danger is benchmark overfitting. An agent can get better at the visible task while getting worse everywhere else.
Step 1: establish a baseline
Start with a clean baseline run. Record the model, prompt, tools, skill versions, memory state, and runner configuration. Without that, you cannot tell whether a later improvement came from the agent or from a changed environment.
The baseline should include passing and failing tasks. Perfect baselines are not useful for improvement. You need failure modes.
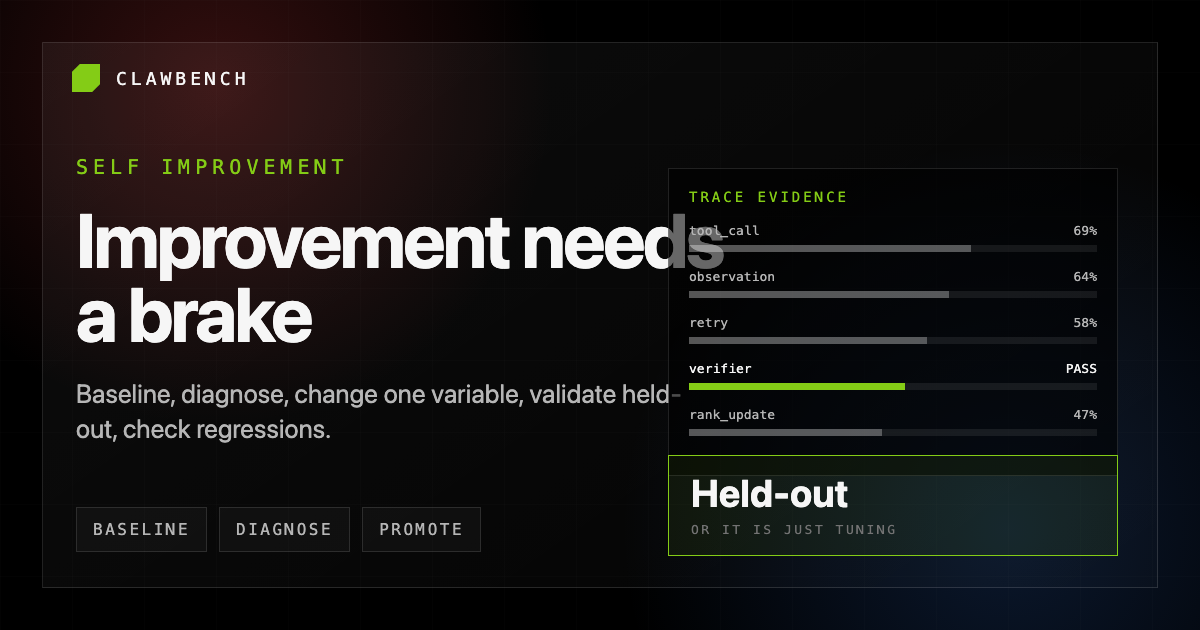
Step 2: diagnose from traces
Do not let the agent invent an improvement from the final score alone. Make it inspect traces. The trace shows whether the failure came from missing context, wrong tool selection, brittle planning, poor recovery, or an invalid assumption.
A good diagnosis names one failure mode. "Improve the prompt" is not a diagnosis. "The agent failed to inspect package scripts before running tests" is.
Step 3: change one variable
Change one thing at a time: prompt, skill, tool policy, memory retrieval, model, or context strategy. If you change five things, you may get a better score and still learn nothing.
The best self-improvement systems keep a change log that explains the intended behavioral effect. That log becomes part of the agent's memory and review trail.
Step 4: validate held-out
This is the brake. Without held-out validation, the agent can overfit to the task that inspired the change.
Held-out tasks should share the underlying behavior but differ in surface form. If the improvement was "inspect package scripts before running tests", the held-out tasks should use different repositories and scripts. If the skill still transfers, it is more likely to be real.
Step 5: check regressions
Every agent improvement can create a new failure. A more cautious tool policy may reduce unsafe commands and increase incomplete runs. A richer memory policy may improve recovery and introduce stale context. A stronger model may improve reasoning and cost too much.
Regression checks keep the loop honest.
| Gate | Question | Promotion Decision |
|---|---|---|
| Baseline delta | Did the target failure improve? | Continue only if yes |
| Held-out check | Did the behavior transfer? | Reject overfit changes |
| Regression check | Did other tasks degrade? | Hold or narrow the change |
| Cost check | Did success get too expensive? | Promote only if viable |
Production promotion
Promotion should be boring. The change passes the target task, passes held-out validation, avoids regressions, keeps cost acceptable, and leaves evidence that a human can inspect.
That is self-improvement you can trust. Everything else is a benchmark optimization loop pretending to be learning.
Practical rule
A self-improving agent loop needs a brake. If held-out validation is missing, do not call it self-improvement. Call it tuning.
Continue the evaluation
Use this guide with the benchmark entity pages, leaderboard context, and trace evidence so the query intent can move straight from explanation to product proof.